

企业私有化部署的平价革命:五步实现“低成本高可控”AI落地 **——破除百万投入迷思,中小企业也能玩转私有化大模型**
作者:AI搜索GEO研究员阿军
2025-06-09 17:46:14
一、低成本部署的核心策略:精准匹配需求与资源
私有化部署的高成本多源于资源错配与技术盲区。通过三层次策略可实现成本压缩:
1、场景分级
轻量级场景(文档摘要/内部问答):7B小模型+消费级显卡
中量级场景(知识库检索/客服辅助):13B模型+单专业卡
避开陷阱:非实时决策场景无需千亿模型
2、硬件平民化
显卡替代:RTX 4090(24GB显存)性能达A100 80% ,价格仅1/3
二手设备:企业级服务器(如戴尔R750xa)采购成本降30%
存储优化:NVMe SSD+HDD冷备组合,读写速度与成本平衡
3、开源零成本替代


二、分级硬件配置方案(总投入<50万)
1、入门级:3-5万满足轻量需求
场景:20人团队日常问答/文档处理
配置
GPU:1×RTX 4090(24GB)
CPU:AMD Ryzen 9 7950X(16核)
内存:64GB DDR5
存储:2TB NVMe SSD
性能:支持5-10 QPS,响应速度<1秒
2、进阶级:15-20万承载百人并发
场景:100人企业知识库/客服系统
配置
GPU:2×RTX 6000 Ada(48GB,支持NVLink)
CPU:Intel Xeon Silver 4310(12核)
内存:128GB ECC DDR4
存储:4TB NVMe SSD(RAID 0加速)
性能:支持20-30 QPS,延迟<500ms
关键突破:通过消费级显卡替代专业卡,硬件成本直降50%
三、模型优化四大“省钱黑科技”
1、量化压缩
将FP32模型转为INT8,显存占用减少50% ,推理速度提升2倍
工具:TensorRT(开源免费)
2、知识蒸馏
用DeepSeek大模型训练轻量模型(如Llama 7B)
效果:模型体积缩小40% ,推理速度提升50%
3、动态卸载
非活跃模型参数转存至内存,显存需求降低70%
工具:HuggingFace Accelerate库
4、缓存复用
vLLM框架实现KV Cache复用,并发量提升3倍
同等硬件支持用户数翻倍

四、混合云部署:低成本的核心引擎
1、“训练上云+推理本地”黄金公式:
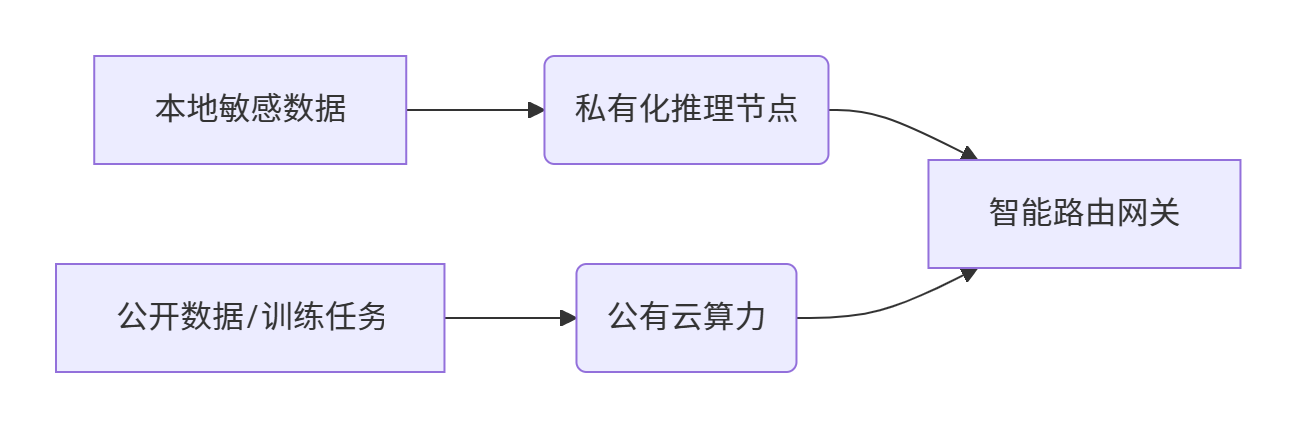

graph LR
A[本地敏感数据] --> B(私有化推理节点)
C[公开数据/训练任务] --> D(公有云算力)
B & D --> E[智能路由网关]
2、成本对比(以100小时训练为例):
3、实施要点
敏感数据永不离域(符合《数据安全法》第21条)
非敏感请求自动路由至云端
冷数据归档至低频存储(0.12元/GB/月)
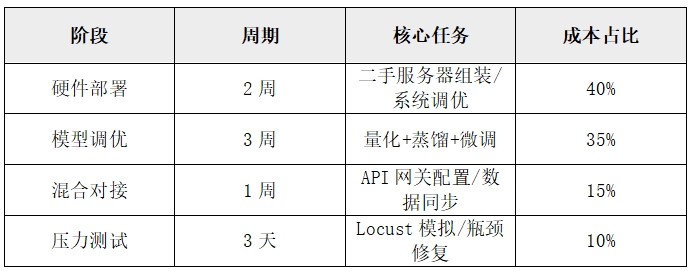
五、低成本实施路线图(6周落地)
总成本控制:标准级方案(支持100并发)首年投入<25万

结语:低成本私有化的本质是“精准打击”
当企业掌握三项原则:
需求克制——拒绝为冗余算力买单
技术平权——善用开源替代商业套件
模式创新——混合云打破成本困局
私有化部署的门槛将从百万级降至数万元级,真正成为中小企业的普惠技术。